
TTS를 공부하고 정리하는 글.
1. TTS(Text to Speech)란?
- 사전적 의미 : 디지털 텍스트(input)를 음성(Output)으로 변환하는 기술
- 통상적 의미 : 음성합성 시스템
2. Tacotron2c
- 구글에서 발표
모델 전체 구조
- 모델의 음성 생성 과정
텍스트로부터 음성 생성 과정을 두 단계로 나누어 수행
- Task1 : 텍스트로부터 Mel-Spectogram을 생성하는 단계
- Sequence to Sequence 딥러닝 구조의 타코트론2 모델
- Task2 : Mel-Spectogram으로부터 음성을 합성하는 단계
- Vocoder로 불리며 WaveNet 모델을 변형하여 사용
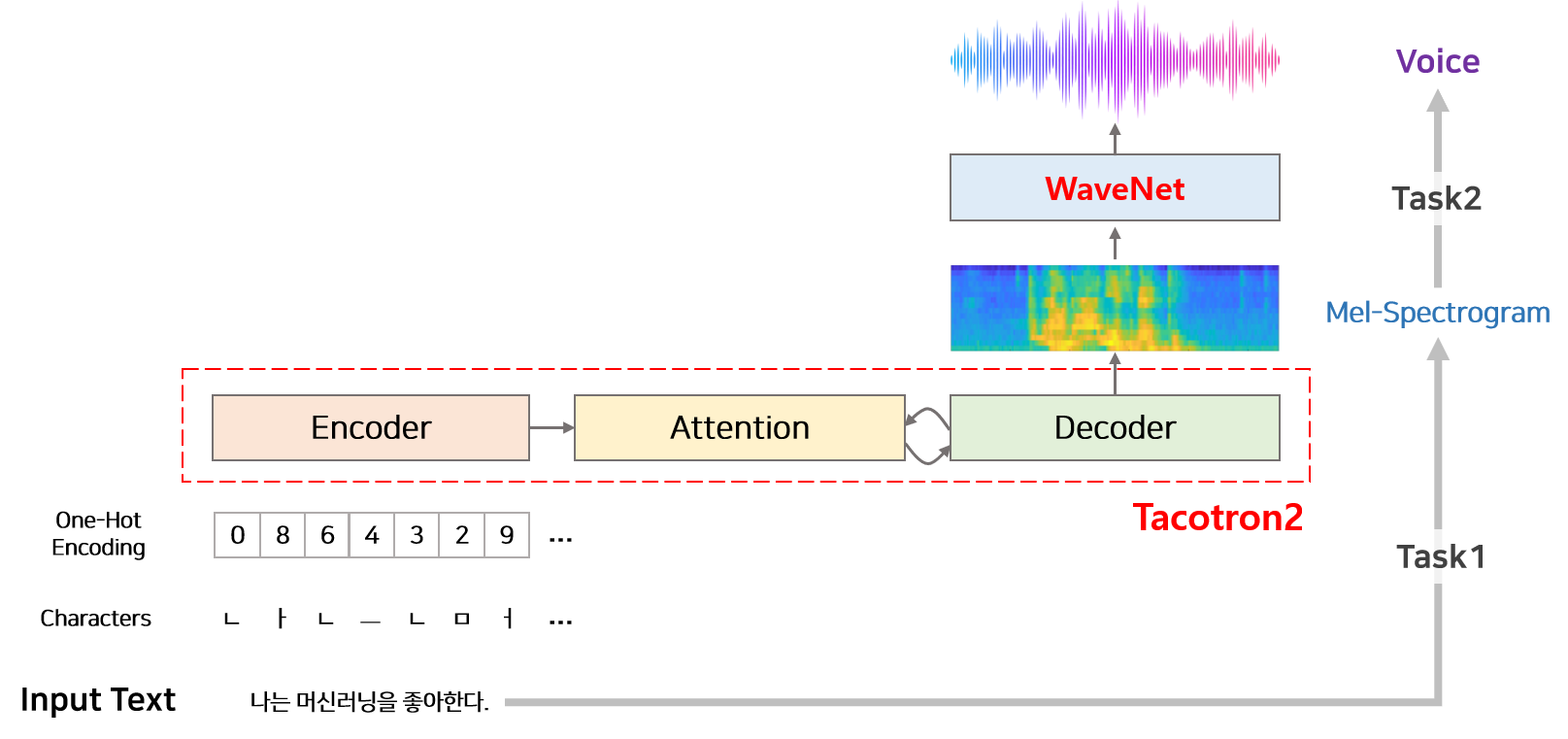
1. Tacotron2(Seq2Sequence)
- Input : character
- Output : mel-spectogram
- Module : Encoder, Decoder, Attention
- Encoder : character를 일련 길이의 hidden vector(feater)로 변환하는 작업
- Attention : Encodr에서 생성된 일정 길이의 hidden vector로부터 시간 순서에 맞게 정보를 추출하여 Decoder에 전달
- Decoder : Attention에서 얻은 정보를 이용하여 mel-spectogram을 생성
1-1. 전처리
모델을 학습하기 위해선 input과 output(label)이 한 쌍으로 묶인 데이터가 필요하다. 텍스트는 character로 만들어야 하고 음성은 Mel-Spectogram으로 변형해야한다.
한글의 경우, 텍스트를 character로 변환할 때에는 음절 을 이용한다. 
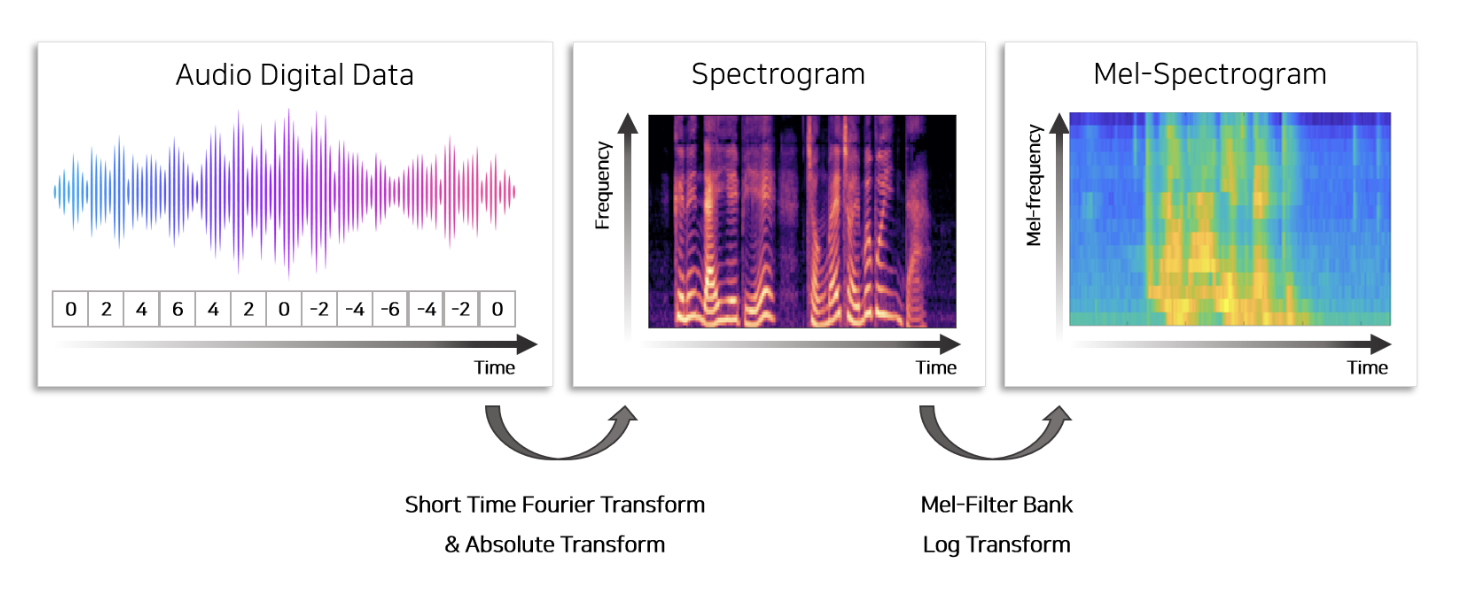
음성 데이터로부터 mel-spectogram을 추출하여 output으로 활용하기 위해선 다음과 같은 과정을 거쳐야한다.
- Short-time Fourier Transform(STFT)
- 80개의 mel filterbank를 이용하여 Mel Scaling
- Log transform
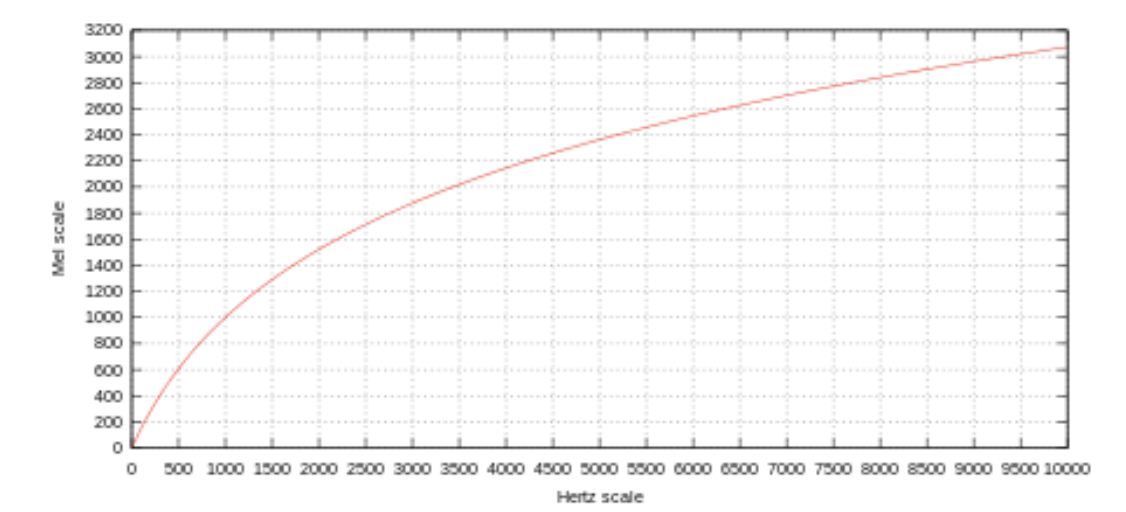
🤔 Mel이란?
인간은 주파수를 linear scale(선형 척도)로 인식하지 못한다. 높은 주파수보다 낮은 주파수에서의 차이를 더 잘 감지한다. 예를 들어, 500Hz와 1000Hz의 차이는 쉽게 구분할 수 있지만, 같은 500Hz 차이임에도 불구하고 10,000Hz와 10,500Hz의 차이는 거의 구분하지 못한다.
1937년에 Stevens, Volkmann, Newmann은 pitch에서 발견한 사람의 음을 인지하는 기준(threshold)을 반영한 sclae 변환 함수를 제안했다. 이것을 mel scale (Melody Scale)이라 한다.
🤔 Pitch란?
음의 높낮이를 뜻한다. 진동수 Hz의 크고 작음과는 다르다. Pitch는 보다 추상적인 개념이다. 사람은 소리의 Hz가 저주파일 때 더 민감하게 인지하고, 고주파로 갈수록 둔감해진다는 점에서 출발한 개념이다. 즉, 사람이 인지하는 음의 높낮이는 Hz와 linear한 관계가 아니라 exponential한 관계이다.
오데오 데이터에는 여러 개의 오디오(frequency)가 섞여 있으므로 여러 개의 오디오를 분리하여 표시하기 위하여 Fourier Transform을 활용한다. 다만 모든 데이터에 Fourier transform을 적용하면 시간에 따른 오디오의 변화를 반영할 수 없으므로 sliding window를 이용하여 오디오를 특정 길이로 잘라 Fourier Transofrm을 적용한다. 이 결과물을 spectogram이라고 하며 오디오로부터 spectogram을 만드는 과정을 shor-time Fourier Transoform이라고 한다.
Spectogram에 mel-filter bank라는 비선형 함수를 적용하여 저주파(low frequency) 영역을 확대하는 작업이다. 사람의 귀는 고주파보다 저주파에 민감하므로 저주파의 영역을 확대하고 고주파의 영역을 축소하여 feature로 사용한다. 이는 더 명료한 음성을 생성하기 위하여 feature를 사람이 쉽게 인지 가능한 sclae로 변환하는 작업이다.
log를 취해 amplitude 영역에서의 log scaling을 진행하면 mel-spectogram이 생성되며 모델의 output(label)로 활용한다.
1-2. Encoder
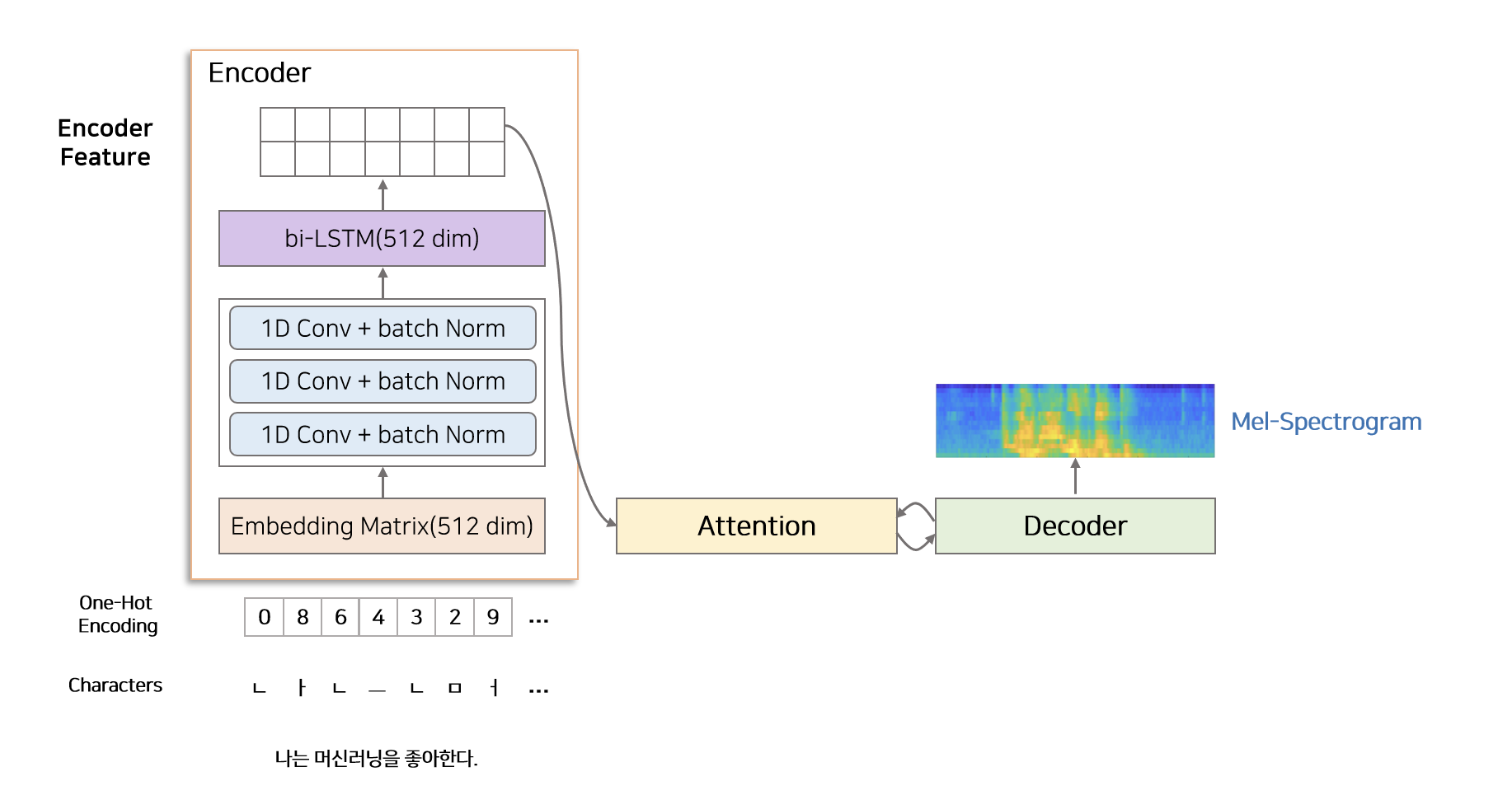
Encoder는 chracter 단위의 one-hot vector를 encoded feature로 변환하는 역할을 한다. Encoder는 Character Embedding, 3 Convolution layer, Bidirectional LSTM으로 구성된다.
input으로 one-hot vector로 변환된 정수열이 들어오면 Embedding matrix를 통해 512차원의 embedding vector로 변환된다. embedding vector는 3개의 conv-layer(1d convolution layer + batch norm)를 지나 bi-LSTM layer로 들어가서 encoded feature로 변환된다.
1-3. Attention
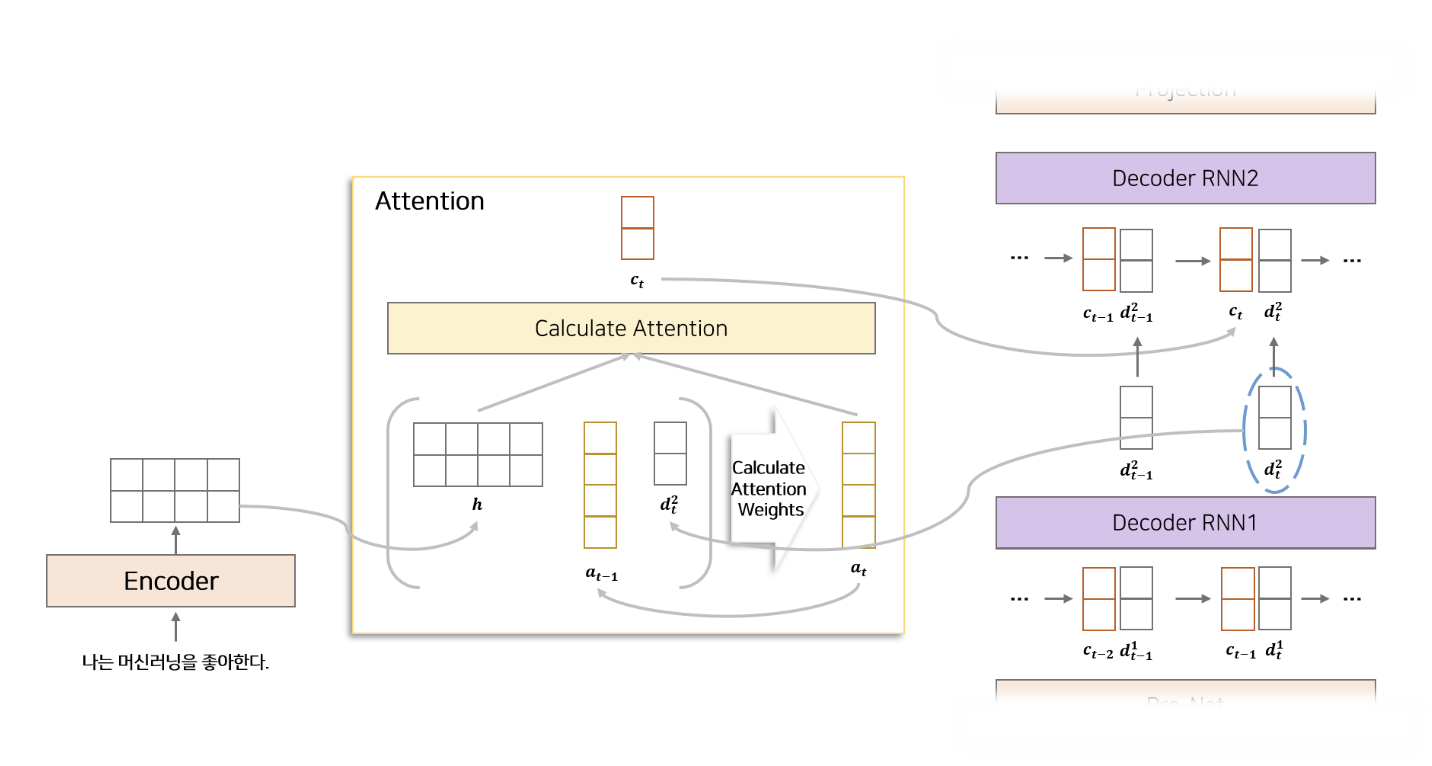
매 시점 Decoder에서 사용할 정보를 Encoder에서 추출해서 가져오는 역할. 즉, Attention mechanism은 Encoder의 LSTM에서 생성된 feature와 Decoder의 LSTM에서 전 시점에서 생성된 feature를 이용하여 Encoder로 부터 어떤 정보를 가져올지 alignment 하는 과정을 의미. Tacotron2 모델은 attention에 Location Sensitive Attention을 사용한다. Locatin Sensitive Attention 이란 Additive attention mechanism(Bandau Attention)에 attention alignment 정보를 추가 한 상태이다.
🤔 alignment
입력 시퀀스(예: 소스 문장)의 각 요소와 출력 시퀀스(예: 대상 문장)의 각 요소 사이의 관계를 매핑하는 과정을 의미한다. 이는 모델이 출력 시퀀스의 각 요소를 생성할 때, 입력 시퀀스의 어떤 부분에 주목해야 하는지 결정하는 데 도움을 준다.
예를 들어, 기계 번역에서 소스 문장의 특정 단어가 대상 문장의 특정 단어를 생성하는 데 얼마나 중요한지를 결정하는 것이 alignment의 한 예이다. 이 과정은 Decoder가 현재 시점에서 어떤 Encoder의 출력(즉, Encoder에서 생성된 feature)에 주목해야 하는지를 결정하여, 해당 정보를 바탕으로 적절한 출력을 생성할 수 있도록 한다.
1-4. Decoder
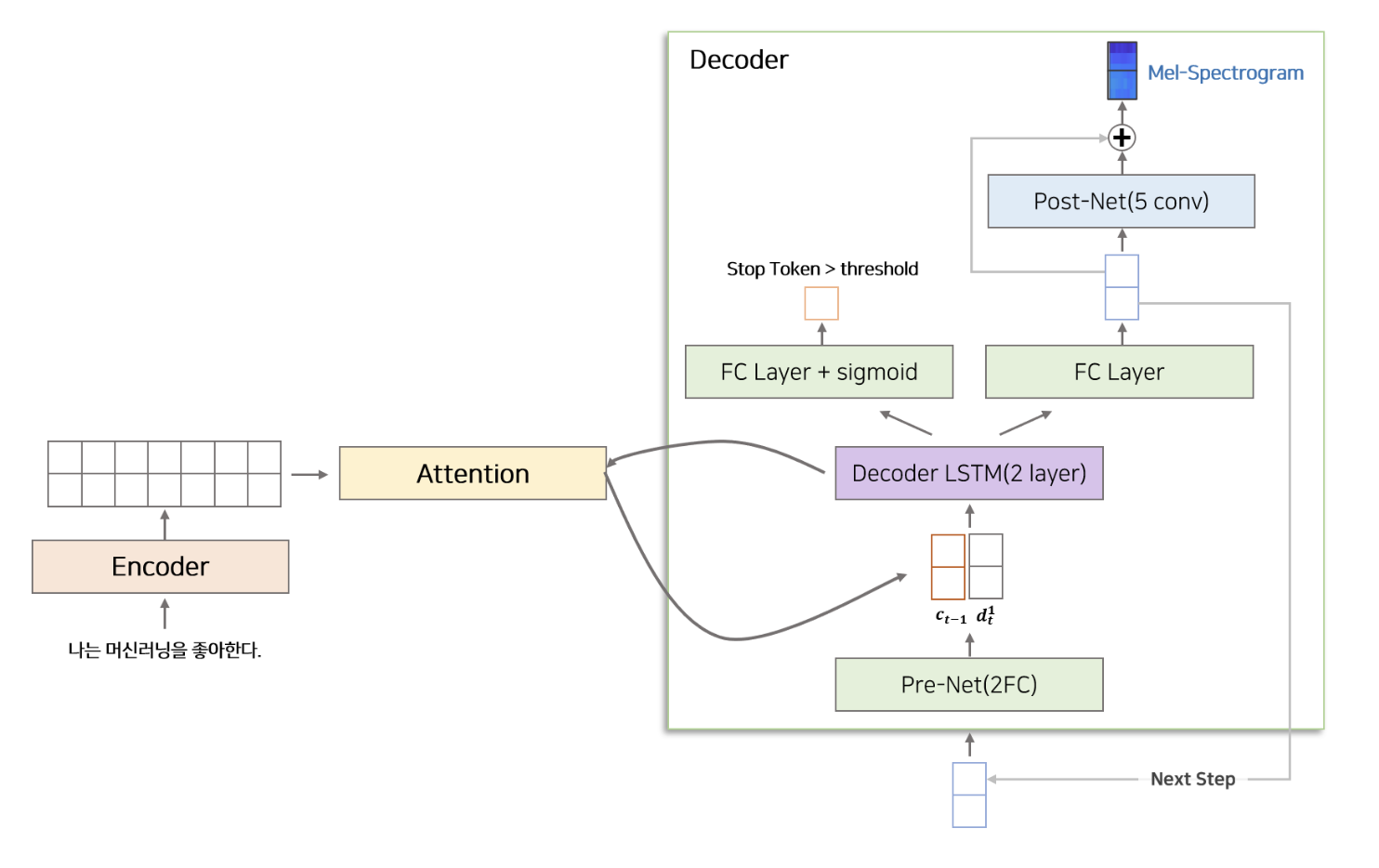
Attention을 통해 얻은 alignment feature와 이전 시점에서 생성된 mel-spectogram 정보를 이용하여 다음 시점 mel-spectogram을 생성하는 역할. Decoder는 Pre-Net, Decoder LSTM, Projection Layer, Post-Net으로 구성된다.
Pre-Net : 2개의 Fully Connected Layer(256dim) + ReLU로 구성된다. 이전 시점에서 생성된 mel-spectogram이 decoder의 input으로 들어오면 가장 먼저 Pre-Net을 통과한다. 또한 bottle-neck 구간으로써 중요 정보를 거르는 역할을 한다.
🤔 bottle-neck
데이터 처리 과정에서 특정 단계나 레이어가 전체 성능에 대한 제한 요소가 되는 경우 사용.
정보의 압축: 병목 구간을 통해 네트워크는 더 중요한 정보를 압축하고 강조하는 반면, 불필요한 정보는 걸러내는 과정을 거친다. 이는 특히 중요한 특징이나 패턴을 학습하는데 도움을 준다.
과적합 방지: 네트워크가 너무 많은 정보나 노이즈에 초점을 맞추지 않도록 제한하는 역할을 함으로써, 모델이 과적합되는 것을 방지할 수 있다.
효율성 향상: bottle neck 구간은 모델의 계산 효율성을 향상시킬 수 있다. 네트워크가 처리해야 하는 정보의 양을 줄임으로써, 더 빠르고 경제적인 연산이 가능해진다.
특징 학습 강화: 특정 구간에서 정보를 압축하고 필터링하는 과정은 네트워크가 더 중요하고 유의미한 특징을 학습하도록 강제할 수 있다. 이는 모델의 예측 성능을 향상시키는 데 기여한다.
Decoder LSTM : 2개의 uni-directional LSTM layer(1024dim) 으로 구성된다. Pre-Net을 통해 생성된 vector와 이전 시점(t-1)에서 생성된 context vector를 합친 후 Decoder LSTM을 통과한다. Decoder LSTM은 Attention Layer의 정보와 Pre-Net으로부터 생성된 정보를 이용하여 특정 시점(t)에 해당하는 정보를 생성한다.
Decoder LSTM에서 생성된 매 시점(t) vector는 두 개로 분기되어 처리된다.
종료 조건의 확률을 개산하는 경로
- Decoder LSTM으로부터 매 시점 생성된 vector를 Fully Connected layer를 통과시킨 후 sigmoid 함수를 취하여 0 과 1 사이의 확률로 변환한다. 이 확률이 Stop 조건에 해당하며 사용자가 설정한 threshold를 넘을 시 inference 단계에서 mel-spectogram 생성을 멈추는 역할을 한다.
mel-spectogram을 생성하는 경로
- Decoder LSTM으로부터 매 시점 생서돈 vector와 Attention에서 생성된 context vector를 합친 후 Fully Connected Layer를 통과시킨다. 이렇게 생성된 mel-vector는 inference 단계에서 Decoder의 다음 시점의 input이 된다.
Post-Net : 5개의 1D Convolution layer로 구성된다. Convolution Layer는 512개의 filter와 5 x 1 kernel size를 가지고 있다. 이전 단계에서 생성된 mel-vector는 Post-Net을 통과한 뒤 다시 mel-vector와 구조(Residual Connection)로 이루어져 있다. Post-Net은 mel-vector를 보정하는 역할을 하며 타코트론2 task1의 최종 결과물인 mel-spectogram의 품질을 높이는 역할을 한다.
1-5. Loss
Tacotron2로부터 생성된 mel-spectogram과 실제 mel-spectogram의 MSE(Mean Squared Error) 를 이용하여 모델을 학습한다.
3. WaveNet Vocoder(Voice Encoder)
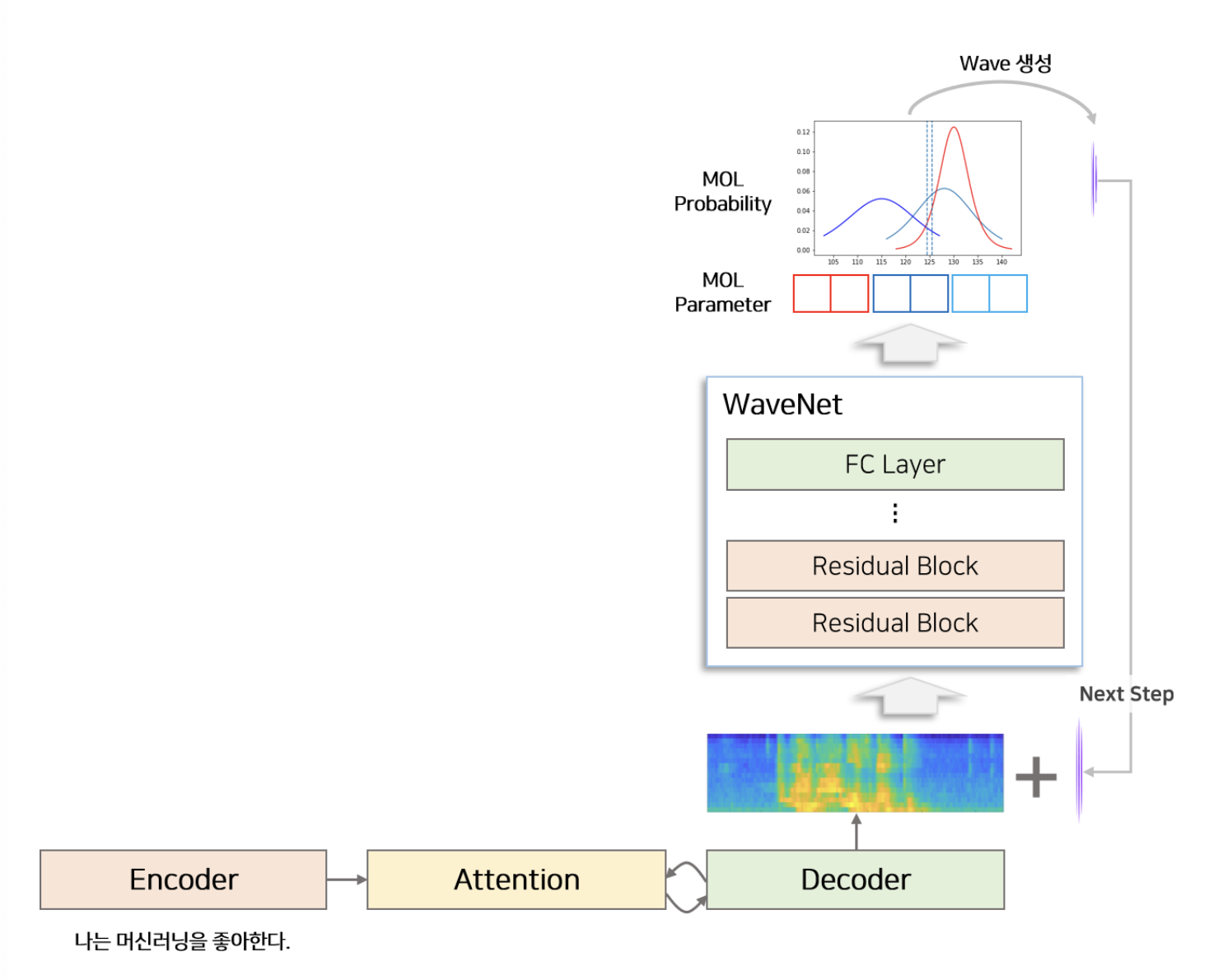
Vocoder는 mel-spectogram으로부터 Waveform(음성)을 생성하는 모듈을 의미한다. 본 논문에서는 WaveNet의 구조를 조금 변경한 모델을 Vocoder로 사용한다. WaveNet 논문에서는 Softmax 함수를 이용하여 매 시점 $ -2^{15}$ ~ $2^{15} + 1 $ 사이의 숫자가 나올 확률을 추출하고 waveform을 생성한다. 이를 수정하여 Mixture Of Logistic distribution(MOL)을 이용하여 $ -2^{15}$ ~ $2^{15} + 1 $ 사이의 숫자가 나올 확률을 생성한다. 이 중 가장 큰 확률을 갖고 있는 값을 이용하여 waveform을 생성한다.
WaveNet Loss
WaveNet으로부터 생성된 waveform과 실제 waveform의 시점 별 Negative log-likelihood Loss를 이용하여 모델을 학습한다.
4. 학습 설정
Tacotron2, WaveNet을 학습할 때 teacher-forcing 을 사용한다. Tacotron2 는 이전 시점에서 생성된 mel-spectogram과 encoder feature를 이용하여 다음 시점 mel-spectogram을 생성한다. training 단계에서는 input을 이전 시점에서 Tacotron2로부터 생성된 mel-spectogram을 사용하지 않고 ground-truth mel-spectogram을 사용하여 학습 효율을 증가시킨다. WaveNet을 학습 할 때도 input으로 Wavenet의 이전 단계에서 생성된 waveform을 사용하는 것이 아닌 ground-truth waveform을 이용한다.
5. 평가
모델을 평가하기 위한 데이터로 24.6시간짜리 한 사람의 음성을 담은 US English dataset을 이용했다. 피실험자에게 음성을 들려주고 1점에서 5점까지 0.5점씩 증가하여 점수를 츨정하는 Mean Opinion Score(MOS) 테스트를 진행했다.
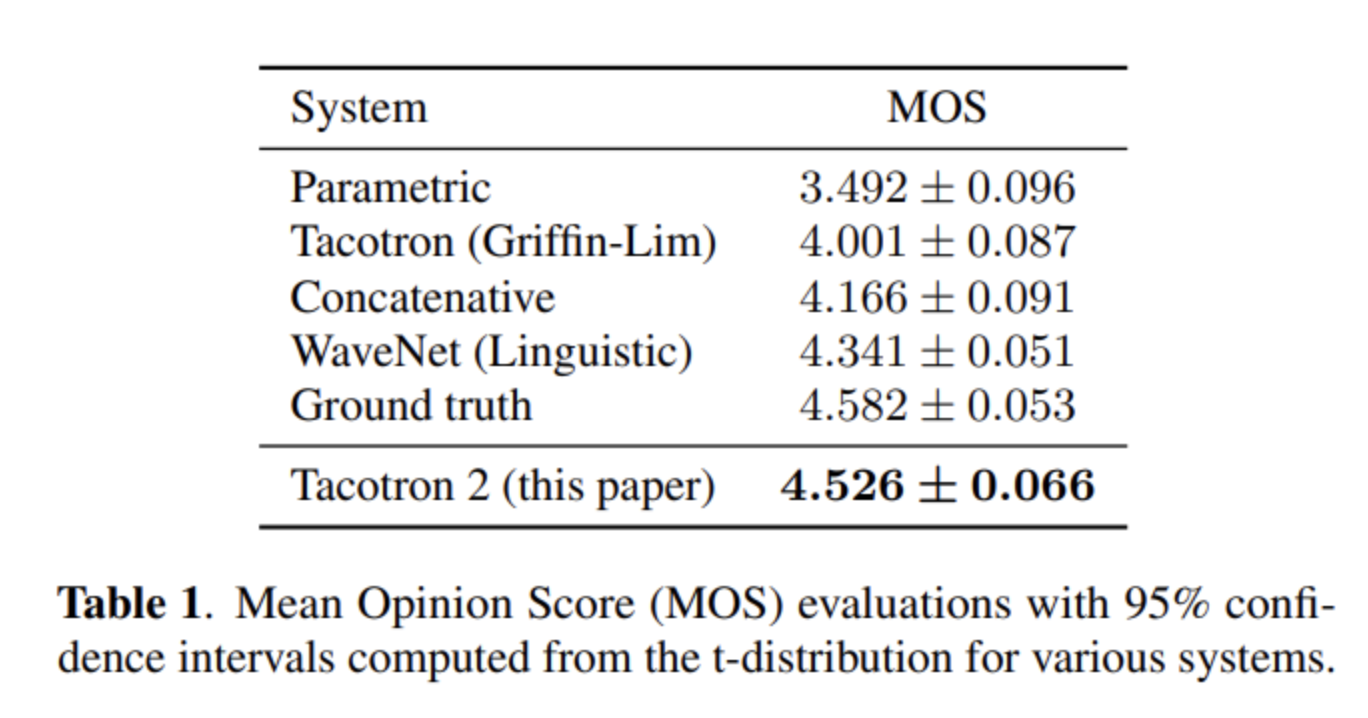
Tacotron2로부터 생성된 음성이 Ground truth와 비슷한 평가를 받은 것을 확인할 수 있다.