
CER과 WER에 대해 알아보자
한국어는 왜 CER로 계산해야하는가?
CER과 WER
- WER : Word Error Rate
- CER : Character Error Rate
WER과 CER의 계산 방법은 거의 동일하다. 띄어쓰기로 구분되는 토큰들의 총 개수에 대비되는 insertion, deletion, substitution의 수가 얼마나 많은지를 계산한다. 차이는 WER은 단어가 토큰이 되며, CER은 문자가 토큰이 된다.
예를 들어, ‘어서 빨리 퇴근하고 싶어요’ 라는 문장은 다음과 같이 계산된다.
- WER : 단어의 개수 -> ‘어서’, ‘빨리’, ‘퇴근하고’, ‘싶어요’ -> 4개
- CER : 문자의 개수 -> ‘어’, ‘서’, ‘빨’, ‘리’, ‘퇴’, ‘근’, ‘하’, ‘고’, ‘싶’, ‘어’, 요’ -> 11개
수식은 다음과 같다.
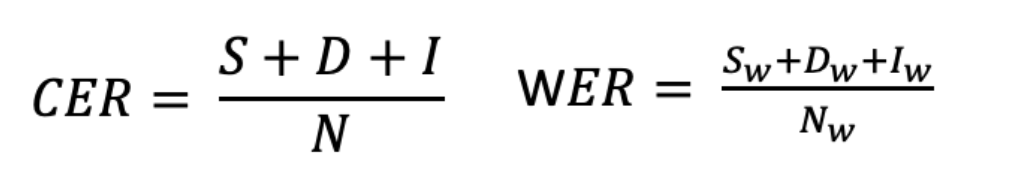
- S : 대체 오류, 철자가 틀린 외자(uniliteral) / 단어(word) 횟수
- D : 삭제 오류, 외자 / 단어의 누락 횟수
- I : 삽입 오류, 잘못된 외자 / 단어가 포함된 회수
- N : 참조의(Ground truth) 외자 / 단어 수
이 떄, STT의 결과가 다음과 같이 나왔다고 가정하자.
- 정답값 : 어서 빨리 퇴근하고 싶어요
- 예측값 : 어서 빨리 퇴근하고 시퍼요
위 예시의 경우 계산은 다음과 같이 된다.
- WER
- ‘시퍼요’ 라는 단어에 대체 오류가 있다.
- 따라서 1 / 4 = 0.25
- CER
- ‘시’, ‘퍼’ 두 문자에 대체 오류가 있다.
- 따라서 2 / 11 = 0.18
한국어는 왜 CER로 계산해야하는가?
위 결과로 보았듯 CER과 WER의 값은 동일한 문장에 대해서도 다르게 나온다. 그렇다면 한국어는 왜 CER로 계산해야할까? 한국어는 교착어(첨가어)로 조사를 사용하고 다른 언어와 비교하여 형태소의 구조가 복잡하며, 단어와 단어 사이의 경계가 모호하기 때문이다.
예를 들어, 위 예시의 예측값이 ‘어서 빨리 퇴근하고싶어요’ 라고 나왔다면, WER의 경우 0.25, CER의 경우 0 이 나온다.
CER은 1이 넘을 수 있다.
가끔 계산을 하다보면 CER이 1이 넘는 경우가 있다. 1이 넘으면 100%가 넘는다는 소리인데 뭔가 이상하다.
그러나 수식적으로 가능하다
예를 들어, 다음과 같은 정답값과 예측값이 있다고 가정하자.
- real : 안녕
- pred : 안녀어어어어어어어어
이런 경우, S = 1, I = 8, D = 0, N = 2 가 된다. 따라서 9 / 2 = 4.5가 나오게 된다. 즉, 모델이 예측한 값이 완전하게 틀렸거나 할루시네이션 등이 발생할 경우 충분히 1이 넘을 수 있다는 것이다.